导读本次内容介绍了实验策略子人群挖掘系统在因果推断与用户建模方面的能力,包括统一维度表建设、CATE 模型训练、双重差分估计与倾向性得分匹配方法的实现。在落地应用上股票的配资,系统可支持推荐策略优化、产品运营迭代等场景,助力实现更精细化、科学化的业务决策。
主要内容包括以下几个部分:
1. 平台介绍
2. 策略正向子人群
3. 其他因果推断功能
4. 总结
5. 问答
分享嘉宾|罗慰蓝 腾讯音乐 实验平台负责人
编辑整理|陈思永
内容校对|李瑶
出品社区|DataFun
01
平台介绍
腾讯音乐娱乐集团(TME)是中国领先的在线音频娱乐平台,旗下包括 QQ 音乐、酷狗音乐、酷我音乐及全民 K 歌等多个主流平台。
02
策略正向子人群
围绕 TME 实验平台中的一项关键功能——策略正向子人群挖掘,系统介绍其项目背景、数据准备、建模方法及算法实现,旨在全面展示该功能的技术实现路径与落地成效。
1. 项目背景
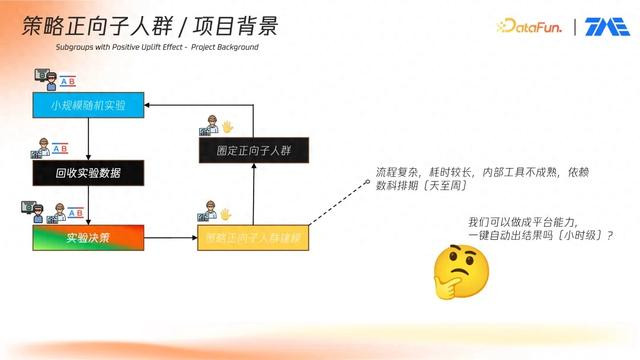
在腾讯音乐的产品迭代过程中,实验平台已成为常规的评估工具。通常流程如下:产品上线新功能后,会通过小规模的垂直随机实验验证效果。平台内的数据科学团队负责回收实验数据并进行分析,以判断功能是否达到推广标准。
然而,在一些情况下,实验组整体效果可能不显著,但部分用户对新功能存在偏好。这种异质性效果提示可进一步探索子人群的响应差异。因此,为识别并圈定对策略响应积极的用户子集,需要通过建模进行精细化分析。
过去,这一过程高度依赖数据科学团队的模型开发与特征工程,再加上排期,周期冗长,影响产品快速迭代。为提升效率,平台提出构建自动化的策略正向子人群挖掘工具,实现一键化分析与报告生成,将周期压缩至小时级别。
2. 解题思路

整个系统分为三个核心阶段:数据准备、条件平均处理效应预估、可视化决策支持。
(1)数据准备
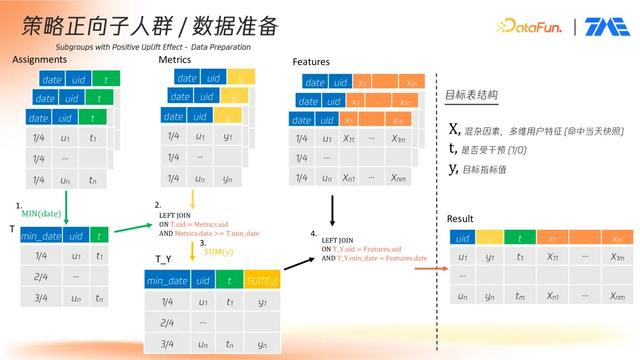
平台底层数据主要由三类表构成:
Assignments 表:记录用户是否命中实验组及命中的时间点;
Metrics 表:记录实验期间用户的各项行为指标;
Features 表:包含用户在实验起始日的静态和动态特征。
首先,提取每位用户最早命中实验或对照组的日期,作为分析起点。随后,将该信息与 Metrics 表进行关联,获取干预后的一段时间内的行为指标,并进行聚合计算,生成每位用户的一条指标记录。
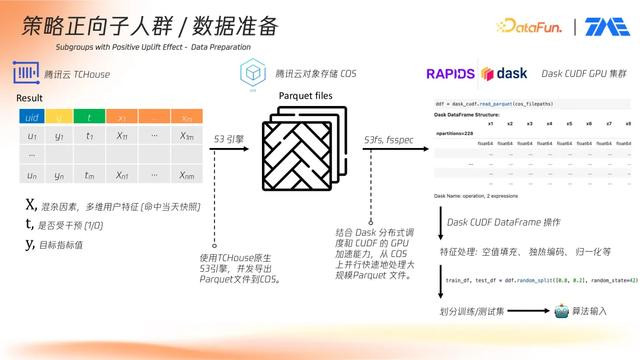
紧接着,通过关联 Features 表,提取用户在命中实验当日的画像特征。最终输出的数据样本包含:X:混杂因素,多维用户特征(命中当天快照);t:是否受干预(1/0);y:目标指标值。该数据经处理后导出为 Parquet 文件,上传至腾讯云 COS,并通过 S3 引擎转换为 Dask CUDF DataFrame 结构,便于在 GPU 集群中进行并行处理。
(2)条件平均处理效应预估

建模目标为条件平均处理效应预估(Conditional Average Treatment Effect,简称 CATE),即给定用户画像特征 X,预测其在接受策略干预与否两种状态下的预期指标差值。
此类估计的挑战在于,无法同时观测到用户在干预与未干预状态下的指标(潜在结果不可同时观测)。因此,平台采用多种因果推断方法对 CATE 进行估计,主要包括:
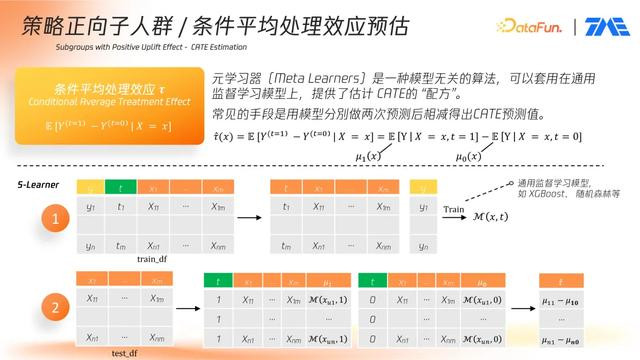
S-Learner(单模型法): 将是否干预(t)作为特征的一部分,与用户画像特征(X)一起输入同一个模型,训练后分别以 t=1 与 t=0 两种情境对同一用户进行预测,差值即为提升值。
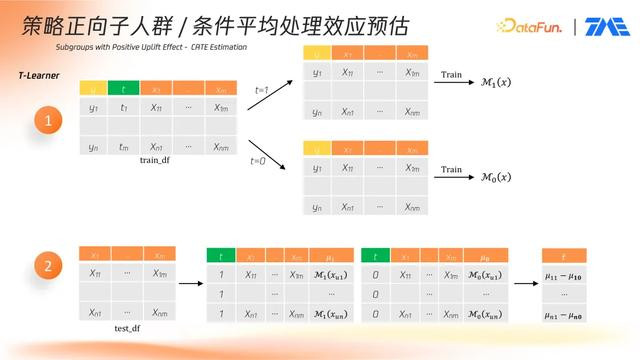
T-Learner(双模型法): 分别对实验组与对照组样本训练两个独立模型。预测时,同一用户的特征输入两个模型,分别得出干预状态与非干预状态下的指标值,二者差值即为提升估计。
T-Learner 存在对组间样本量平衡的依赖。当实验组与对照组样本规模差距过大时,模型表现容易失衡。
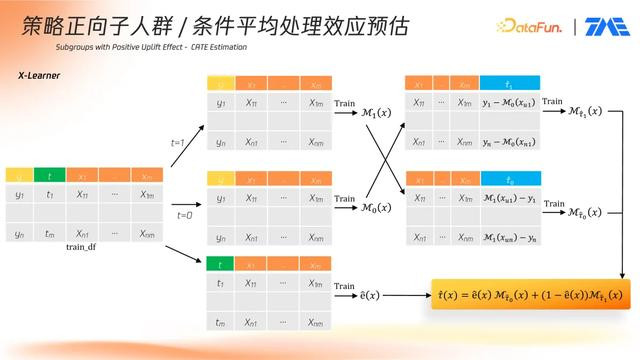
X-Learner: X-Learner 在训练集中分别对实验组和对照组训练出 2 个模型后,因为我们训练数据中 y 也是已知。所以,我们可以对训练集中的对照组用户用实验组训练出来的模型预测对照组用户如在实验组的指标,得到对照组用户 Uplift 预估;同时,对训练集中的实验组用户用对照组训练出来的模型预测实验组用户如在对照组的指标,得到实验组用户 Uplift 预估。我们再用这两个预估值和对应用户再分别建出两个直接用特征估计 Uplift 的模型。所以需要预测新用户时,我们手上就会有对 2 个 Uplift 预估,我们再用 propensity score 对 2 个预估值得出最终 Uplift 预估结果。如果对照组用户比实验组用户人多很多,那 propensity score 大概率就比较小,实验组的 Uplift 预估权重就会大点(1-propensity score),而实验组的 Uplift 预估是在第一阶段中用对照组用户数据建模出来的指标估计 y, 所以按理更好,因为对照组用户人多。所以 X-learner 就可以较好的解决组 T-Learner 的样本不平衡问题。
平台支持多种底层算法进行模型训练,包括 XGBoost、LightGBM、Random Forest 等。训练任务均在 GPU 集群中并行执行,显著提升了训练效率与泛化性能。

表示学习:
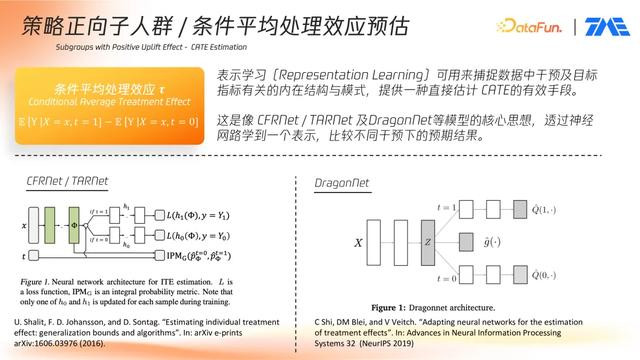
除传统 Meta-Learner 架构外,近年来的 CATE 建模中也引入了表示学习方法。这类方法通过学习实验组和对照组的共享表示,增强模型泛化能力。例如,
①基于双头神经网络的建模
此类方法为实验组与对照组分别构建两套输出头。在训练过程中,若样本属于实验组,仅更新实验组头及共享层权重;反之则更新对照组相关权重。通过这种方式,网络可以分别拟合实验与对照条件下的响应函数。在推理阶段,将用户特征输入网络,输出两个分支的结果后取差值,即可获得该用户的 uplift 值。
②DragonNet 模型
DragonNet 在结构上与上述双头网络类似,但额外增加一个倾向性打分(Propensity Score)头。在训练过程中,根据样本所属组别更新相应路径,最终输出三个量:实验响应值、对照响应值与倾向性得分。响应值差值部分即为所需的 CATE。
训练过程中,模型只更新对应组别的输出头及其共享表示层的参数,从而实现了更好的参数共享与因果效应建模。最终预测阶段,输入用户特征后模型可同时输出 treatment 与 control 条件下的预测值,两者之差即为 uplift 值。
③模型评估 – 提升曲线下面积
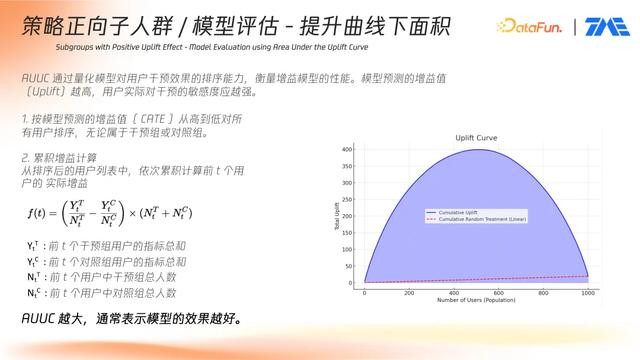
在实验平台部署多个 CATE 模型后,如何评估其效果成为关键。常用评估指标为 AUUC(Area Under the Uplift Curve)。
评估流程如下:
将所有样本按照预测 uplift(增益值) 值从高到低排序;
分桶计算每个分位下实验组与对照组的平均指标差值;
绘制 uplift 曲线并计算其曲线下面积;
面积越大,模型对干预敏感度越高,效果越好。
④模型超参数调优 –Optuna
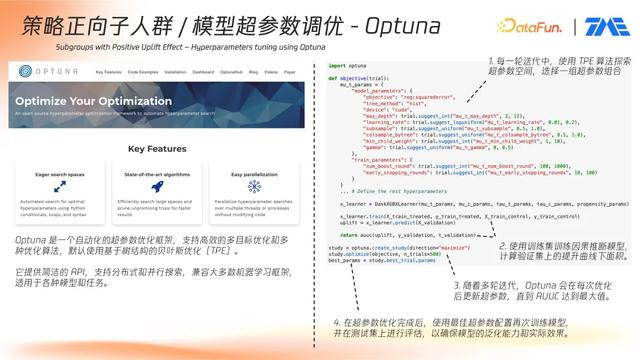
在此基础上,通过行业通用的超参优化框架(如 Optuna)实现超参调优。框架可自动遍历指定模型空间和参数组合,通过贝叶斯优化、TPE 树结构搜索等策略寻找最优组合。整体流程如下:
定义模型结构与搜索空间;
运行若干轮模型训练与验证;
每轮训练后评估验证集上的 AUUC;
迭代更新搜索策略,最终输出最优超参组合。
训练完成后,会在测试集上再次验证性能,以决定最佳模型。
3. 结果可视化
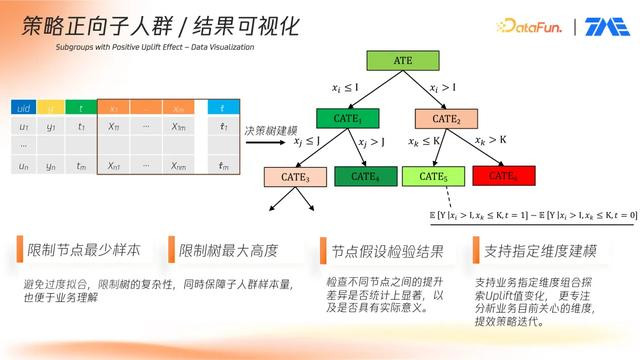
模型预测结束后,可通过 uplift 预测值结合用户特征构建简化版可解释模型——决策树。该树结构用于从众多特征中提取具策略意义的分裂路径,便于策略制定。
此过程属于“二阶段建模”流程:第一阶段使用全部特征训练 uplift 模型,第二阶段建立解释型模型,满足业务可理解性要求。
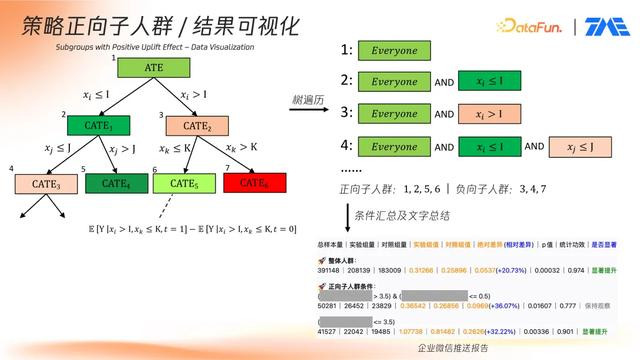
完成树结构后:
提取正向 uplift 最大的人群路径与负向路径;
汇总分裂条件,形成可操作策略;
自动生成文字报告,通过企业微信等平台推送产品经理,辅助业务决策。
该流程打通了从建模、评估到解释的全链路,实现对策略正向人群的自动化建模与可视化输出。
4. 全流程总结
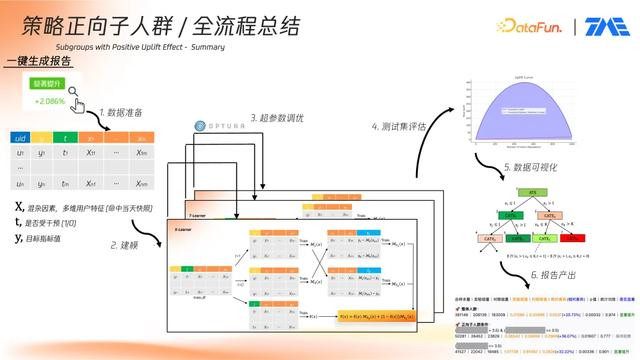
整套建模流程已嵌入实验平台,并通过自动化管道支持模型训练、评估、调参、可视化与报告生成。该流程可在半小时至一小时内完成原本需数天手动完成的策略建模任务,平台具备如下特性:
支持多种因果推断模型(Meta-Learners、表示学习法等);
内置自动特征表与共享维度仓,避免人工特征准备;
支持模型训练、调参、评估、可视化与报告输出的全流程;
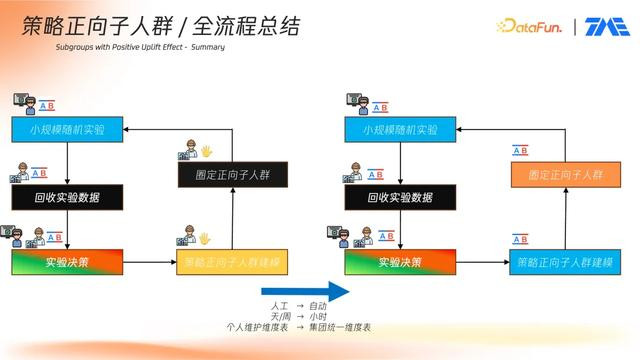
在默认设置下,单轮建模至报告输出可于半小时至一小时内完成;
03
其他因果推断功能
1. 双重差分
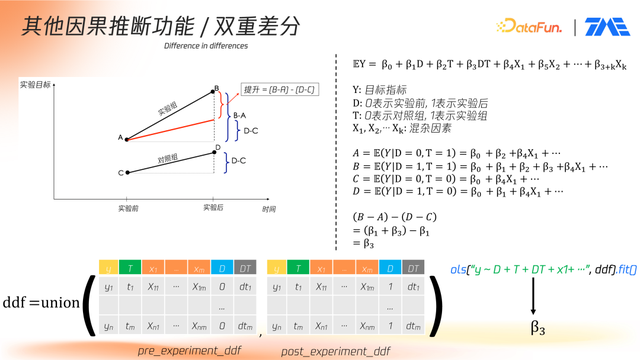
平台支持经典的差分法,用于处理实验组与对照组在实验前即存在的初始差异问题。在实际应用中,实验前两组的指标值往往存在偏差,若直接比较实验后指标,将导致因果效应估计失真。因此,差分法通过计算“(实验组后 - 实验组前)-(对照组后 - 对照组前)”的净效应来剥离背景差异影响。
具体实现中,构建如图的线性回归模型;
通过对该模型进行线性回归拟合,可以直接得到 β3 及其置信区间,实现差分法下的因果估计。
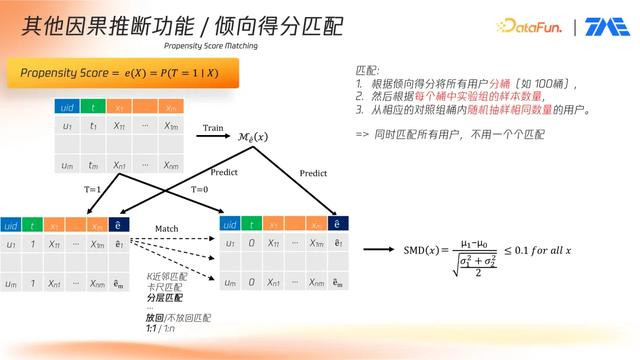
2. 倾向得分匹配
平台同样提供倾向性得分匹配(PSM)能力,用于非随机试验场景下的因果推断。该方法通过构建一个二分类模型,预测用户接受干预的概率(即“倾向性得分”),再基于该得分对实验组和对照组用户进行匹配,从而实现可比性人群筛选。
整体流程如下:
建模倾向性得分:以用户特征 X₁ ~ Xₘ 为输入,自变量为是否接受干预(0 或 1),训练一个模型(如逻辑回归、XGBoost 等),输出每个用户属于实验组的概率。
分桶抽样匹配:将倾向性得分离散化为多个区间(如将得分区间 [0,1] 等分为 100 个桶),统计实验组每个桶中的人数,并在对照组中按照对应分布抽样,实现整体匹配。
匹配效果评估:匹配完成后,针对每一个用户特征计算标准化平均差异(SMD),判断匹配是否有效。一般认为 SMD
该方式相比传统一对一匹配,显著提升了效率,且在实际项目中通过桶级匹配的方式实现全量人群的一致匹配。
04
总结
本次分享聚焦介绍了平台核心的因果推断功能--策略正向子人群控掘,并深入剖析其数据科学流程、工程实现与应用思考。同时,简要介绍其他因果推断功能,帮助大家更全面了解其他应用场景。
因果推断是从表象到本质理解的关键步骤。我们将持续深化技术能力,拓展应用边界,助力业务更科学的决策与更可解释的策略。
05
问答
1. 模型落地与系统集成
平台构建的人群挖掘能力并非停留在建模阶段,还具备较强的业务应用能力,尤其是在推荐算法与策略运营场景中的集成:
(1)推荐系统协同
在推荐算法场景中,建模输出的正向显著人群并不直接用于干预推荐模型结构,而是通过分析哪些特征对 uplift(增益值)贡献显著,为推荐算法提供决策灵感。推荐算法团队可以在已有框架下手动加入这些特征,提升模型表达能力与解释性。
(2)精细化运营支持
在人群策略落地方面,运营或产品团队可基于平台输出的人群规则,在画像平台中圈选目标用户,执行下一轮实验或策略迭代。这种方式实现了策略的精细化分发与循环优化,尤其适用于非推荐类业务场景。
(3)闭环实验验证
对于通过 uplift 建模识别出正向响应人群,可继续在下轮实验中聚焦这些人群执行干预,形成以因果推断为核心的迭代式优化流程。例如,在不更改推荐算法本身的前提下,通过设置受试人群条件,仅对预期响应显著的群体进行推荐实验,有助于在业务层面更精确地释放价值。
2. 结果建模与因果树的分离实现
虽然最终的效果与因果树模型相似,但平台采用“两步建模”方式以获得更大的建模灵活性。具体而言,首先使用 CATE 类方法确定 uplift 显著人群,再基于这些结果与特征构建决策树,实现对人群结构的可视化与解释。这一方式允许用户在构建 uplift 模型时自由使用丰富特征,而在可视化建模时聚焦于业务关注维度,提高了算法的业务适应性与可解释性。
以上就是本次分享的内容,谢谢大家。
 股票的配资
股票的配资
一鼎盈配资提示:文章来自网络,不代表本站观点。
相关文章


沪深京指数
热点资讯
